3 Norme, prodotti scalari ortogonalità

3.1 Norme di vettori
Consideriamo un vettore \bm{x} \in \Bbb{R}^3 con componenti x_1, x_2, e x_3. Le componenti di questo vettore possono essere interpretate come le coordinate di un punto nello spazio tridimensionale \Bbb{R}^3. La distanza di questo punto dall’origine è la lunghezza del segmento che collega l’origine al punto \bm{x}. Questa lunghezza può essere vista come la lunghezza del vettore \bm{x}. Dal teorema di Pitagora1, la lunghezza del vettore \bm{x} è data da:
\sqrt{x_1^2 + x_2^2 + x_3^2}.
Possiamo estendere questa nozione di lunghezza a vettori in \Bbb{R}^n o \Bbb{C}^n con la seguente definizione. Per ogni vettore \bm{x} \in \Bbb{R}^n o \Bbb{C}^n, definiamo la sua norma euclidea come:
\|\bm{x}\|_2 = \sqrt{\sum_{i=1}^{n} |x_i|^2}.
Questa misura è chiamata la lunghezza del vettore e possiede le seguenti proprietà:
Non negatività: La norma è sempre non negativa, \|\bm{x}\|_2 = \sqrt{\sum_{i=1}^{n} |x_i|^2} \geq 0. Inoltre, \|\bm{x}\|_2 = 0 solo se tutte le componenti sono zero, cioè \bm{x} = \bm{0}.
Omogeneità: Moltiplicare il vettore per uno scalare \alpha modifica la norma come segue: \begin{aligned} \|\alpha \bm{x}\|_2 &= \sqrt{\sum_{i=1}^{n} |\alpha x_i|^2} \\ &= \sqrt{\sum_{i=1}^{n} |\alpha|^2 |x_i|^2} \\ &= |\alpha| \sqrt{\sum_{i=1}^{n} |x_i|^2} \\ &= |\alpha| \|\bm{x}\|_2. \end{aligned}
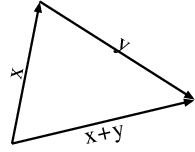
Disuguaglianza triangolare: Per ogni coppia di vettori \bm{x}, \bm{y} \in \Bbb{K}^n, si ha: \|\bm{x} + \bm{y}\|_2 \leq \|\bm{x}\|_2 + \|\bm{y}\|_2. \tag{3.1} Questa è nota come disuguaglianza triangolare. Il termine “triangolare” si riferisce alla proprietà geometrica dei triangoli, dove la lunghezza di un lato è sempre minore o uguale alla somma delle lunghezze degli altri due lati. Questo concetto è illustrato nella figura Figure 3.1.
3.2 Diseguaglianze di Young2,Hölder3 e Minkowski4.
La dimostrazione della disuguaglianza triangolare (Equation 3.1) è un po’ laboriosa e richiede l’uso di alcune disuguaglianze classiche, come quella di Young.
Lemma 3.1 (Disuguaglianza di Young) Dati due numeri reali p e q tali che
\dfrac{1}{p}+\dfrac{1}{q} = 1, \qquad 1 < p, q < \infty,
allora per ogni coppia di numeri reali non negativi a e b si ha
ab \leq \dfrac{a^p}{p} + \dfrac{b^q}{q}. \tag{3.2}
Inoltre, la disuguaglianza diventa uguaglianza se a^p = b^q.
Proof. Consideriamo la funzione
f(t) = \dfrac{t}{p} - t^{1/p}. \tag{3.3}
Allora, calcoliamo la derivata prima della funzione:
f'(t) = \dfrac{1}{p} - \dfrac{t^{1/p-1}}{p} = \dfrac{1}{p} - \dfrac{t^{-1/q}}{p} = \dfrac{1}{p} \left(1 - t^{-1/q}\right). \tag{3.4}
Poiché \frac{1}{q} < 1, abbiamo che f'(t) < 0 per 0 < t < 1 e f'(t) > 0 per t > 1. Quindi, t = 1 è un punto di minimo per f(t) in (0, \infty), e di conseguenza f(t) \geq f(1) per t > 0. Pertanto,
f(t) \geq f(1), \qquad \text{cioè} \qquad \dfrac{t}{p} - t^{1/p} \geq \dfrac{1}{p} - 1 = - \dfrac{1}{q}.
Da qui otteniamo:
t^{1/p} \leq \dfrac{1}{q} + \dfrac{t}{p}.
Osserviamo che se a = 0 o b = 0, la disuguaglianza è banalmente vera. Consideriamo quindi a, b > 0 e calcoliamo la disuguaglianza in t = a^p b^{-q}:
ab^{-q/p} \leq \dfrac{1}{q} + \dfrac{a^p b^{-q}}{p}.
Moltiplicando la disuguaglianza per b^q ed osservando che q - q/p = 1, otteniamo il risultato cercato:
ab \leq \dfrac{a^p}{p} + \dfrac{b^q}{q}.
Infine, osserviamo che se a^p = b^q, allora calcoliamo la disuguaglianza in t = 1, ottenendo l’uguaglianza:
ab = \dfrac{a^p}{p} + \dfrac{b^q}{q}.
Possiamo ora dimostrare la disuguaglianza di Hölder
Theorem 3.1 (Disuguaglianza di Hölder) Dati due numeri reali p e q tali che 1 < p, q < \infty e che soddisfano 1/p + 1/q = 1, e dati a_1, a_2, \ldots, a_n \geq 0 e b_1, b_2, \ldots, b_n \geq 0, allora
\sum_{k=1}^{n} a_k b_k \leq \left(\sum_{k=1}^{n} a_k^p\right)^{1/p} \left(\sum_{k=1}^{n} b_k^q\right)^{1/q}.
Proof. Sia
A = \left(\sum_{k=1}^{n} a_k^p\right)^{1/p}, \qquad B = \left(\sum_{k=1}^{n} b_k^q\right)^{1/q}.
Se AB = 0, allora o A = 0 oppure B = 0 5. Questo implica che tutti gli a_k sono zero, e quindi la disuguaglianza è banalmente vera. Lo stesso ragionamento si applica nel caso in cui B = 0.
Supponiamo quindi che AB > 0. Utilizzando la disuguaglianza Equation 3.2 del lemma Lemma 3.1, otteniamo per ogni k:
Supponiamo, per esempio, che A \neq 0 e B \neq 0.
\dfrac{a_k}{A} \cdot \dfrac{b_k}{B} \leq \dfrac{a_k^p}{p A^p} + \dfrac{b_k^q}{q B^q}.
Sommando su tutti i k, abbiamo:
\dfrac{\displaystyle\sum_{k=1}^{n} a_k b_k}{AB} \leq \dfrac{\displaystyle\sum_{k=1}^{n} a_k^p}{p A^p} + \dfrac{\displaystyle\sum_{k=1}^{n} b_k^q}{q B^q}.
Osservando che
A^p = \sum_{k=1}^{n} a_k^p \quad\text{e}\quad B^q = \sum_{k=1}^{n} b_k^q
possiamo scrivere:
\dfrac{\sum_{k=1}^{n} a_k b_k}{AB} \leq \dfrac{A^p}{p A^p} + \dfrac{B^q}{q B^q} = \dfrac{1}{p} + \dfrac{1}{q} = 1.
Infine, dimostriamo la disuguaglianza di Minkowski
Theorem 3.2 (Disuguaglianza di Minkowski) Sia 1 \leq p < \infty; e siano a_1, a_2, \ldots, a_n \geq 0 e b_1, b_2, \ldots, b_n \geq 0. Allora si ha:
\left( \sum_{k=1}^{n} (a_k + b_k)^p \right)^{1/p} \leq \left( \sum_{k=1}^{n} a_k^p \right)^{1/p} + \left( \sum_{k=1}^{n} b_k^p \right)^{1/p}.
Proof. Il caso p = 1 è immediato e risulta banale. Consideriamo ora il caso p > 1.
Iniziamo con l’espandere:
\sum_{k=1}^{n} (a_k + b_k)^p = \sum_{k=1}^{n} a_k (a_k + b_k)^{p-1} + \sum_{k=1}^{n} b_k (a_k + b_k)^{p-1}.
Applicando la disuguaglianza di Hölder a ciascuna delle due somme, con q definito dalla relazione 1/p + 1/q = 1, otteniamo:
\begin{aligned} \sum_{k=1}^{n} (a_k + b_k)^p &\leq \left( \sum_{k=1}^{n} a_k^p \right)^{1/p} \left( \sum_{k=1}^{n} (a_k + b_k)^{q(p-1)} \right)^{1/q} \\ &\quad + \left( \sum_{k=1}^{n} b_k^p \right)^{1/p} \left( \sum_{k=1}^{n} (a_k + b_k)^{q(p-1)} \right)^{1/q}. \end{aligned}
Dividendo entrambi i lati dell’ineguaglianza per \left( \sum_{k=1}^{n} (a_k + b_k)^p \right)^{1/q} e notando che q(p-1) = p, otteniamo la disuguaglianza desiderata.
Osserviamo che la disuguaglianza di Minkowski per p=2 è proprio la Equation 3.1.
Possiamo estendere la nozione di lunghezza di un vettore attraverso una generalizzazione della funzione \|,\cdot,\| che mantenga le tre proprietà precedentemente menzionate.
3.3 Alcune proprietà delle norme vettoriali
Continuità delle norme
Theorem 3.3 La norma vettoriale è una funzione uniformemente continua dallo spazio dei vettori \Bbb{K}^n in \Bbb{R}.
Proof. La continuità uniforme della norma segue immediatamente dalla disuguaglianza:
\Big|\,\|\bm{x}\| - \|\bm{y}\|\,\Big| \leq \|\bm{x} - \bm{y}\|,
che dimostra che la norma è uniformemente continua.
Equivalenza delle norme
Theorem 3.4 Siano \|\cdot\|^{'} e \|\cdot\|^{''} due norme in \Bbb{K}^n. Esistono due costanti \alpha > 0 e \beta > 0 tali che, per ogni \bm{x} \in \Bbb{K}^n, vale:
\alpha \|\bm{x}\|^{''} \leq \|\bm{x}\|^{'} \leq \beta \|\bm{x}\|^{''}.
Proof. Se \bm{x} = \bm{0}, il teorema è ovvio. Per \bm{x} \neq \bm{0}, proviamo l’affermazione considerando il caso particolare in cui \|\cdot\|^{''} è la norma \|\cdot\|_{\infty}. Il caso generale seguirà per confronto.
Definiamo l’insieme:
S = \{\bm{y} \in \Bbb{K}^n \mid \|\bm{y}\|_{\infty} = 1\}.
L’insieme S è chiuso e limitato, quindi compatto. Poiché la norma \|\cdot\|^{'} è continua, essa raggiunge un minimo strettamente positivo \alpha e un massimo \beta su S.
Per ogni \bm{x} \in \Bbb{K}^n, possiamo scrivere:
\bm{y} = \frac{\bm{x}}{\|\bm{x}\|_{\infty}} \in S.
Di conseguenza, abbiamo:
\alpha \leq \|\bm{y}\|^{'} = \left\|\frac{\bm{x}}{\|\bm{x}\|_{\infty}}\right\|^{'} \leq \beta,
che implica:
\alpha \|\bm{x}\|_{\infty} \leq \|\bm{x}\|^{'} \leq \beta \|\bm{x}\|_{\infty}.
Confronto tra norme standard
Per ogni vettore \bm{x} \in \Bbb{K}^n, valgono le seguenti disuguaglianze:
\begin{aligned} (i) \qquad & \|\bm{x}\|_{\infty} & \leq & \|\bm{x}\|_2 & \leq & \sqrt{n} \|\bm{x}\|_{\infty}, \\ (ii) \qquad & \|\bm{x}\|_2 & \leq & \|\bm{x}\|_1 & \leq & \sqrt{n} \|\bm{x}\|_{\infty}, \\ (iii)\qquad & \|\bm{x}\|_{\infty} & \leq & \|\bm{x}\|_1 & \leq & n \|\bm{x}\|_{\infty}. \end{aligned}
Proof. Le disuguaglianze si ottengono nei seguenti modi:
(i) Sia \|\cdot\|' = \|\cdot\|_2. Ogni vettore \bm{y} \in S = \{\bm{y} \in \Bbb{K}^n \mid \|\bm{y}\|_{\infty} = 1\} ha almeno una componente di modulo 1, diciamo la componente y_k, con 1 \leq k \leq n, mentre le altre componenti soddisfano |y_i| \leq 1 per i \neq k.
Pertanto, si ha:
\|\bm{y}\|_2^2 = 1 + \sum_{i=1 \atop i \neq k}^{n} |y_i|^2 \quad \forall \, \bm{y} \in S,
da cui segue che:
\begin{aligned} \alpha &= \min_{\bm{y} \in S} \|\bm{y}\|_2 = 1, \\ \beta &= \max_{\bm{y} \in S} \|\bm{y}\|_2 = \sqrt{n}. \end{aligned}
Quindi, si ottiene:
\|\bm{x}\|_{\infty} \leq \|\bm{x}\|_2 \leq \sqrt{n} \|\bm{x}\|_{\infty}.
(ii) La prima disuguaglianza di (ii) si ottiene notando che, per ogni \bm{x} \in \Bbb{K}^n,
\|\bm{x}\|_2^2 = \sum_{i=1}^{n} |x_i|^2 \leq \left( \sum_{i=1}^{n} |x_i| \right)^2 = \|\bm{x}\|_1^2.
La seconda disuguaglianza deriva dalla disuguaglianza di Cauchy-Schwarz:
|(\bm{x}, \bm{y})| \leq \|\bm{x}\|_2 \|\bm{y}\|_2,
applicata a un vettore ausiliario \bm{y} definito da:
y_i = \begin{cases} \frac{x_i}{|x_i|}, & \text{se} \, x_i \neq 0, \\ 0, & \text{se} \, x_i = 0. \end{cases}
Si osserva che:
|(\bm{x}, \bm{y})| = \sum_{i=1}^{n} |x_i| = \|\bm{x}\|_1,
e
\|\bm{y}\|_2 = \left( \sum_{i=1}^{n} |y_i|^2 \right)^{\frac{1}{2}} = \sqrt{n}.
Quindi, otteniamo:
\|\bm{x}\|_2 \leq \|\bm{x}\|_1 \leq \sqrt{n} \|\bm{x}\|_{\infty}.
(iii) Le disuguaglianze si ottengono combinando i risultati di (i) e (ii):
\|\bm{x}\|_{\infty} \leq \|\bm{x}\|_1 \leq n \|\bm{x}\|_{\infty}.
Definition 3.1 (p-Norma) Utilizzando la disuguaglianza di Minkowski (Equation 3.1), si dimostra che per 1 \leq p < \infty, la funzione definita come
\|\bm{x}\|_{p} = \left( \sum_{k=1}^{n} |x_k|^{p} \right)^{1/p}
è una norma. Questa norma è chiamata p-norma.
Due casi particolari di p-norma sono:
Norma 1: \|\bm{x}\|_1 = \displaystyle\sum_{i=1}^{n} |x_i|.
Norma 2: \|\bm{x}\|_2 = \sqrt{\displaystyle\sum_{i=1}^{n} |x_i|^{2}}.
Inoltre, è possibile estendere la definizione della norma al caso limite p \to \infty:
\|\bm{x}\|_{\infty} = \max_{k=1, \ldots, n}|x_k|,
e si può verificare facilmente che anche questa funzione è una norma.
3.4 Prodotti scalari
Il prodotto scalare tra due vettori è molto usato in fisica ed ha la seguente definizione
Definition 3.2 (Prodotto Scalare (Euclideo)) Il prodotto scalare (o prodotto dot) tra due vettori \bm{a} e \bm{b} è dato dalla formula:
\bm{a} \cdot \bm{b} = \|\bm{a}\|_2 \|\bm{b}\|_2 \cos \theta_{\bm{a} \bm{b}}, \tag{3.5}
dove \theta_{\bm{a} \bm{b}} rappresenta l’angolo compreso tra i due vettori \bm{a} e \bm{b}.
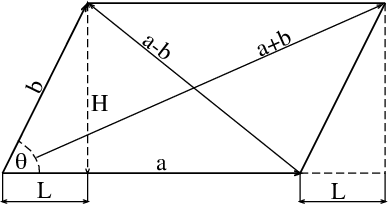
Dalla figura 6 Figure 3.2 possiamo derivare una formula per il prodotto scalare che non utilizza il coseno, ma solo la norma.
Consideriamo le seguenti definizioni:
L = \|\bm{b}\|_2 \cos \theta_{\bm{a} \bm{b}}, \qquad H = \|\bm{b}\|_2 \sin \theta_{\bm{a} \bm{b}},
dove \theta_{\bm{a} \bm{b}} è l’angolo tra i vettori \bm{a} e \bm{b}. Applicando il teorema di Pitagora, otteniamo:
\|\bm{a} + \bm{b}\|_2^2 - H^2 = (\|\bm{a}\|_2 + L)^2 = \|\bm{a}\|_2^2 + L^2 + 2\|\bm{a}\|_2 L \tag{3.6}
e
\|\bm{a} - \bm{b}\|_2^2 - H^2 = (\|\bm{a}\|_2 - L)^2 = \|\bm{a}\|_2^2 + L^2 - 2 \|\bm{a}\|_2 L \tag{3.7}
Sottraendo l’equazione Equation 3.7 da Equation 3.6, otteniamo:
\|\bm{a} + \bm{b}\|_2^2 - \|\bm{a} - \bm{b}\|_2^2 = 4 \|\bm{a}\|_2 L = 4 \|\bm{a}\|_2 \|\bm{b}\|_2 \cos \theta_{\bm{a} \bm{b}},
e quindi, utilizzando la formula Equation 3.5, possiamo scrivere:
\bm{a} \cdot \bm{b} = \frac{\|\bm{a} + \bm{b}\|_2^2 - \|\bm{a} - \bm{b}\|_2^2}{4}.
Inoltre, osserviamo che:
\|\bm{a} + \bm{b}\|_2^2 - \|\bm{a} - \bm{b}\|_2^2 = \sum_{k=1}^{n} \left[|a_k + b_k|^2 - |a_k - b_k|^2\right] = 4 \sum_{k=1}^{n} a_k b_k,
da cui il prodotto scalare si esprime come:
\bm{a} \cdot \bm{b} = \sum_{k=1}^{n} a_k b_k. \tag{3.8}
Questa formula è valida per vettori reali. Per un vettore complesso \bm{a}, la formula Equation 3.8 non restituisce direttamente il quadrato della lunghezza, poiché se a_k sono numeri complessi:
\bm{a} \cdot \bm{a} = \sum_{k=1}^{n} a_k^2 \neq \sum_{k=1}^{n}|a_k|^2.
Tuttavia, è possibile modificare la definizione di prodotto scalare per ottenere una formula che, applicata a vettori reali, sia equivalente a Equation 3.5 e che, nel caso di vettori complessi, restituisca \bm{a} \cdot \bm{a} = \|\bm{a}\|_2^2.
Definition 3.3 (Prodotto Scalare nel Campo Complesso) Definiamo il prodotto scalare tra due vettori \bm{x} e \bm{y} di dimensione n come:
\bm{x} \cdot \bm{y} = \sum_{i=1}^{n} x_i \overline{y_i}, \tag{3.9}
dove \overline{\bm{z}} denota il coniugato complesso di un numero complesso \bm{z}.
Ricordiamo che:
\overline{a + \mathrm{i} b} = a - \mathrm{i} b
e il coniugato complesso soddisfa le seguenti proprietà:
\begin{aligned} \overline{z} \cdot z & = (a + \mathrm{i} b)(a - \mathrm{i} b) = a^2 + b^2 = |z|^2, \\ \overline{\overline{z}} & = \overline{a - \mathrm{i} b} = a + \mathrm{i} b = z, \\ \overline{z + w} &= \overline{z} + \overline{w}, \end{aligned}
oltre a:
\begin{aligned} \overline{zw} &= \overline{(a + \mathrm{i} b)(c + \mathrm{i} d)} = \overline{(ac - bd) + (bc + ad) \mathrm{i}} \\ &= (ac - bd) - (bc + ad) \mathrm{i}, \\ \overline{z} \cdot \overline{w} &= (a - \mathrm{i} b)(c - \mathrm{i} d) \\ &= ac - bd - (bc + ad) \mathrm{i}, \end{aligned}
da cui segue:
\overline{zw} = \overline{z} \cdot \overline{w}.
Per un numero complesso z = a + \mathrm{i} b, abbiamo:
\Re(z) = \frac{z + \overline{z}}{2} = a, \qquad \Im(z) = \frac{z - \overline{z}}{2 \mathrm{i}} = b.
La formula Equation 3.9 è nota come prodotto scalare euclideo.
Questa funzione soddisfa le seguenti proprietà:
Non negatività e nullità: \bm{x} \cdot \bm{x} = \sum_{i=1}^{n} x_i \overline{x_i} = \sum_{i=1}^{n} |x_i|^2 \geq 0. Inoltre, \bm{x} \cdot \bm{x} = 0 se e solo se x_i = 0 per tutti i, il che implica \bm{x} = \bm{0}.
Simmetria: \bm{x} \cdot \bm{y} = \sum_{i=1}^{n} x_i \overline{y_i} = \overline{\sum_{i=1}^{n} \overline{x_i} y_i} = \overline{\bm{y} \cdot \bm{x}}.
Linearità: (\bm{x} + \bm{y}) \cdot \bm{z} = \sum_{i=1}^{n} (x_i + y_i) \overline{z_i} = \sum_{i=1}^{n} x_i \overline{z_i} + \sum_{i=1}^{n} y_i \overline{z_i} = \bm{x} \cdot \bm{z} + \bm{y} \cdot \bm{z}.
Omogeneità: (\alpha \bm{x}) \cdot \bm{y} = \sum_{i=1}^{n} \alpha x_i \overline{y_i} = \alpha \sum_{i=1}^{n} x_i \overline{y_i} = \alpha (\bm{x} \cdot \bm{y}).
Queste proprietà (1)-(4) possono essere utilizzate per definire il prodotto scalare in modo assiomatico.
Definition 3.4 (Prodotto Scalare in generale) Una funzione \langle\cdot,\cdot\rangle : \Bbb{K}^n \times \Bbb{K}^n \to \Bbb{K} è un prodotto scalare se soddisfa le seguenti proprietà per ogni \bm{x}, \bm{y}, \bm{z} \in \Bbb{K}^n e per ogni \alpha \in \Bbb{K}:
Non negatività e nullità: \langle\bm{x},\bm{x}\rangle \geq 0 \quad \text{e} \quad \langle\bm{x},\bm{x}\rangle = 0 \text{ se e solo se } \bm{x} = \bm{0}.
Simmetria Coniugata: \langle\bm{x},\bm{y}\rangle = \overline{\langle\bm{y},\bm{x}\rangle}, dove \overline{\cdot} denota l’operazione di coniugazione complessa.
Linearità nella prima variabile: \langle\bm{x} + \bm{y},\bm{z}\rangle = \langle\bm{x},\bm{z}\rangle + \langle\bm{y},\bm{z}\rangle.
Omogeneità: \langle\alpha \bm{x},\bm{y}\rangle = \alpha \langle\bm{x},\bm{y}\rangle.
Queste proprietà definiscono il concetto di prodotto scalare in uno spazio vettoriale.
Theorem 3.5 (Disuguaglianza di Cauchy7-Schwarz8) Per un prodotto scalare generico, la disuguaglianza di Cauchy-Schwarz è espressa come:
\boxed{ (\bm{x}, \bm{y}) \leq \|\bm{x}\| \|\bm{y}\| } \tag{3.10}
dove \|\cdot\| rappresenta la norma indotta dal prodotto scalare. La disuguaglianza è stretta solo se \bm{x} e \bm{y} sono allineati, cioè se esiste uno scalare \gamma tale che \bm{x} = \gamma \bm{y}.
Proof. La disuguaglianza è ovvia se uno dei vettori è nullo. Supponiamo quindi che entrambi i vettori siano non nulli. Consideriamo il vettore \bm{x} - \alpha \bm{y} e applicando la proprietà (1) della definizione di prodotto scalare alla sua norma, otteniamo:
(\bm{x} - \alpha \bm{y}, \bm{x} - \alpha \bm{y}) \geq 0.
Sviluppando l’espressione, abbiamo:
\begin{aligned} 0 & \leq (\bm{x} - \alpha \bm{y}, \bm{x} - \alpha \bm{y}) \\ & = (\bm{x}, \bm{x}) - \alpha (\bm{y}, \bm{x}) - \overline{\alpha} (\bm{x}, \bm{y}) + \alpha \overline{\alpha} (\bm{y}, \bm{y}) \\ & = (\bm{x}, \bm{x}) - \alpha \overline{(\bm{x}, \bm{y})} - \overline{\alpha} [(\bm{x}, \bm{y}) - \alpha (\bm{y}, \bm{y})]. \end{aligned} \tag{3.11}
Scegliendo \alpha in modo da annullare l’espressione tra parentesi quadre, otteniamo:
\alpha = \frac{(\bm{x}, \bm{y})}{(\bm{y}, \bm{y})}.
Sostituendo questo valore di \alpha, si ottiene:
0 \leq \|\bm{x}\|^2 - \frac{|(\bm{x}, \bm{y})|^2}{\|\bm{y}\|^2},
che è equivalente alla disuguaglianza di Cauchy-Schwarz espressa in Equation 3.10. Se \bm{x} - \alpha \bm{y} \neq \bm{0}, allora la disuguaglianza è stretta, e quindi anche Equation 3.10 è stretta.
3.5 Ortogonalità e angolo tra vettori
Il concetto di prodotto scalare permette di definire l’ortogonalità e l’angolo tra due vettori. Utilizzando il prodotto scalare euclideo espresso in Equation 3.9 e la formula per il prodotto scalare in Equation 3.5, possiamo calcolare l’angolo \theta_{\bm{a}\bm{b}} tra due vettori \bm{a} e \bm{b} con la seguente formula:
\theta_{\bm{a}\bm{b}} = \arccos \left( \frac{\bm{a} \cdot \bm{b}}{\|\bm{a}\|_2 \|\bm{b}\|_2} \right).
Se l’angolo tra i vettori è 90^{0} allora \cos 90^{0}=0 implica che il loro prodotto scalare è nullo. Questo suggerisce la seguente definizione.
Definition 3.5 (Ortogonalità) Due vettori \bm{a} e \bm{b} si dicono ortogonali se il loro prodotto scalare è nullo. In tal caso, scriviamo \bm{a} \perp \bm{b}, indicando che:
\bm{a} \cdot \bm{b} = 0.
3.6 Prodotto Vettoriale
Consideriamo due vettori \bm{a} e \bm{b} nello spazio tridimensionale \Bbb{R}^3. Vogliamo trovare un terzo vettore \bm{x} che sia ortogonale a entrambi i vettori dati. Algebricamente, il problema può essere formulato come:
\text{Trovare } \bm{x} \in \Bbb{R}^3 \text{ tale che:} \left\{\begin{matrix} \bm{a} \cdot \bm{x} &= 0, \\ \bm{b} \cdot \bm{x} &= 0. \end{matrix}\right.
Espresso in termini delle componenti dei vettori, questo diventa:
\left\{\begin{matrix} a_1 x_1 + a_2 x_2 + a_3 x_3 &= 0, \\ b_1 x_1 + b_2 x_2 + b_3 x_3 &= 0. \end{matrix}\right. \tag{3.12}
Una soluzione a questo sistema di equazioni è data dalle componenti:
\left\{\begin{matrix} x_1 &= a_2 b_3 - a_3 b_2, \\ x_2 &= a_3 b_1 - a_1 b_3, \\ x_3 &= a_1 b_2 - a_2 b_1. \end{matrix}\right. \tag{3.13}
Questa soluzione è conosciuta come prodotto vettoriale e si indica con:
\bm{x} = \bm{a} \wedge \bm{b}.
Inoltre, possiamo verificare la seguente relazione:
(\|\bm{a} \wedge \bm{b}\|_2)^2 + (\bm{a} \cdot \bm{b})^2 = (\|\bm{a}\|_2)^2 (\|\bm{b}\|_2)^2, \tag{3.14}
da cui, utilizzando la formula sopra, otteniamo:
\|\bm{a} \wedge \bm{b}\|_2 = \|\bm{a}\|_2 \|\bm{b}\|_2 \sin \theta_{\bm{a} \bm{b}}.
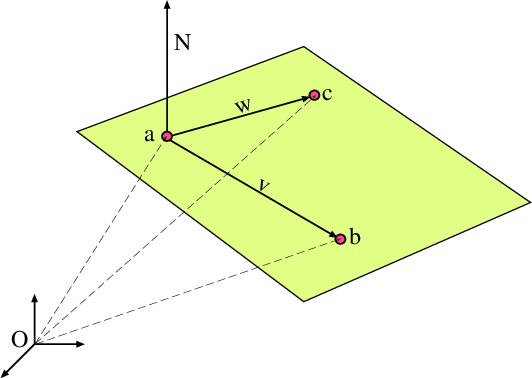
Il prodotto vettoriale è molto utile in geometria nello spazio. Per esempio, per trovare l’equazione di un piano che passa per tre punti distinti \bm{a}, \bm{b}, e \bm{c}, possiamo usare il prodotto vettoriale. Definiamo i vettori:
\bm{v} = \bm{b} - \bm{a}, \quad \bm{w} = \bm{c} - \bm{a},
che sono vettori complanari al piano. Il vettore normale al piano è dato da:
\bm{N} = \bm{v} \wedge \bm{w}.
L’equazione del piano può quindi essere scritta come:
\bm{N} \cdot \bm{x} = \bm{N} \cdot \bm{a}.
3.7 Indipendenza Lineare e Basi in \Bbb{K}^n
Il concetto di dipendenza e indipendenza lineare è fondamentale in algebra lineare.
Definition 3.6 (Indipendenza Lineare) Consideriamo k vettori non nulli \bm{x}_1, \bm{x}_2, \ldots, \bm{x}_k in uno spazio vettoriale. Questi vettori sono detti linearmente dipendenti se esistono degli scalari \alpha_1, \alpha_2, \ldots, \alpha_k, con almeno uno di essi non nullo, tali che:
\alpha_1 \bm{x}_1 + \alpha_2 \bm{x}_2 + \cdots + \alpha_k \bm{x}_k = 0.
Se, invece, non esistono tali scalari e l’unica soluzione all’equazione sopra è quella triviale, cioè tutti gli scalari sono zero, allora i vettori \bm{x}_1, \bm{x}_2, \ldots, \bm{x}_k sono detti linearmente indipendenti.
Consideriamo k vettori linearmente indipendenti in \Bbb{K}^n, denotati con \bm{x}_1, \bm{x}_2, \ldots, \bm{x}_k. Dato un vettore \bm{w} \in \Bbb{K}^n, è possibile che \bm{w} possa essere scritto come una combinazione lineare di questi vettori. In altre parole, esistono scalari \alpha_1, \alpha_2, \ldots, \alpha_k tali che:
\bm{w} = \alpha_1 \bm{x}_1 + \alpha_2 \bm{x}_2 + \cdots + \alpha_k \bm{x}_k.
Questi scalari \alpha_i sono scelti in modo tale che l’equazione sia soddisfatta.
Definition 3.7 (Base) Se i vettori \bm{x}_1, \bm{x}_2, \ldots, \bm{x}_k sono tali che ogni vettore \bm{w} \in \Bbb{K}^n può essere espresso come una combinazione lineare di essi, allora diremo che questi vettori formano una base di \Bbb{K}^n. Affinché ciò accada, è necessario che il numero di vettori k sia uguale alla dimensione dello spazio, cioè k = n.
Inoltre, questa condizione è anche sufficiente. Infatti, se si scelgono n vettori qualsiasi in \Bbb{K}^n che siano linearmente indipendenti, allora questi vettori formano sempre una base di \Bbb{K}^n.
Example 3.1 (Esempio) Consideriamo i vettori \bm{e}_1, \bm{e}_2, \ldots, \bm{e}_n in \Bbb{K}^n, definiti come segue:
\bm{e}_1 = \begin{pmatrix} 1 \\ 0 \\ 0 \\ \vdots \\ 0 \end{pmatrix}, \qquad \bm{e}_2 = \begin{pmatrix} 0 \\ 1 \\ 0 \\ \vdots \\ 0 \end{pmatrix}, \qquad \cdots, \qquad \bm{e}_n = \begin{pmatrix} 0 \\ 0 \\ \vdots \\ 0 \\ 1 \end{pmatrix}.
Questi vettori sono chiaramente linearmente indipendenti. Infatti, se consideriamo la combinazione lineare
\alpha_{1}\bm{e}_1 + \alpha_{2}\bm{e}_2 + \cdots + \alpha_{n}\bm{e}_n = \begin{pmatrix} \alpha_{1} \\ \alpha_{2} \\ \vdots \\ \alpha_{n} \end{pmatrix},
questa sarà nulla se e solo se tutti i coefficienti \alpha_{i} sono zero, cioè \alpha_{i} = 0 per i = 1, 2, \ldots, n.
3.8 Indipendenza lineare dei vettori ortogonali
Theorem 3.6 I k vettori \bm{x}_1, \bm{x}_2, , \bm{x}_k che sono ortogonali a coppie,
\bm{x}_i \bot \bm{x}_j \quad \text{per } i \neq j,
sono necessariamente linearmente indipendenti.
Proof. Supponiamo che esistano k scalari \alpha_{1}, \alpha_{2}, , \alpha_{k} tali che
\alpha_{1}\bm{x}_1 + \alpha_{2}\bm{x}_2 + \cdots + \alpha_{k}\bm{x}_k = \bm{0}.
Per dimostrare che i vettori sono linearmente indipendenti, consideriamo il prodotto scalare di entrambi i lati dell’equazione con il vettore \bm{x}_i per i = 1, 2, \ldots, k. Utilizzando l’ortogonalità dei vettori, otteniamo:
\begin{aligned} 0 &= \bm{x}_i \cdot (\alpha_{1}\bm{x}_1 + \alpha_{2}\bm{x}_2 + \cdots + \alpha_{k}\bm{x}_k), \\ &= \alpha_{1} (\bm{x}_i \cdot \bm{x}_1) + \alpha_{2} (\bm{x}_i \cdot \bm{x}_2) + \cdots + \alpha_{i} (\bm{x}_i \cdot \bm{x}_i) + \cdots + \alpha_{k} (\bm{x}_i \cdot \bm{x}_k). \end{aligned}
Poiché \bm{x}_i \cdot \bm{x}_j = 0 per i \neq j, rimane
0 = \alpha_{i} (\bm{x}_i \cdot \bm{x}_i).
Dato che \bm{x}_i \cdot \bm{x}_i > 0 (perché \bm{x}_i è un vettore non nullo), segue che \alpha_{i} = 0.
Quindi, tutti i coefficienti \alpha_{i} devono essere zero, il che dimostra che i vettori \bm{x}_1, \bm{x}_2, , \bm{x}_k sono linearmente indipendenti.
3.9 Ortonormalizzazione di Gram9-Schmidt10
Definition 3.8 (Vettori ortogonali) Dati k vettori \bm{v}_1, \bm{v}_2,, \bm{v}_k, diremo che gli stessi formano un sistema ortogonale se sono a due a due ortogonali, cioè
\bm{v}_i \bot\bm{v}_j, \qquad i \neq j.
Definition 3.9 (Vettori ortonormali) Dati k vettori \bm{u}_1, \bm{u}_2,, \bm{u}_k, diremo che gli stessi formano un sistema ortonormale se sono a due a due ortogonali e di norma 1, cioè
\|\bm{u}_i\|_2=1, \qquad \bm{u}_i \bot\bm{u}_j, \quad i \neq j.
Definition 3.10 (Span) Dati k vettori \bm{v}_1, \bm{v}_2,, \bm{v}_k, definiremo con \textrm{span}(\bm{v}_1,\bm{v}_2,\ldots,\bm{v}_k) lo spazio vettoriale generato dalle loro combinazioni lineari
\textrm{span}(\bm{v}_1,\bm{v}_2,\ldots,\bm{v}_k)= \left\{ \alpha_1\bm{v}_1+\alpha_2\bm{v}_2+\cdots+\alpha_k\bm{v}_k \;|\; \alpha_1,\alpha_2,\ldots,\alpha_k\in \Bbb{K} \right\}
Dati k vettori \bm{v}_1, \bm{v}_2,, \bm{v}_k, linearmente indipendenti è possibile costruire k vettori \bm{u}_1, \bm{u}_2,, \bm{u}_k a due a due ortogonali e di norma unitaria tali che
\textrm{span}(\bm{v}_1,\bm{v}_2,\ldots,\bm{v}_k) =\textrm{span}(\bm{u}_1,\bm{u}_2,\ldots,\bm{u}_k).
Theorem 3.7 Ortonormalizzazione di Gram-Schmidt
Consideriamo k vettori \bm{v}_1, \bm{v}_2, , \bm{v}_k che sono linearmente indipendenti. Possiamo costruire una nuova sequenza di k vettori ortonormali \bm{u}_1, \bm{u}_2, , \bm{u}_k che soddisfano le seguenti proprietà:
\bm{u}_1 = \dfrac{\bm{v}_1}{\|\bm{v}_1\|_2}:
Il primo vettore \bm{u}_1 è ottenuto normalizzando \bm{v}_1.
\bm{u}_i \bot \bm{u}_j per ogni i \neq j:
I vettori \bm{u}_i sono ortogonali tra loro.
\|\bm{u}_i\|_2 = 1 per ogni i = 1, 2, \ldots, k:
Ogni vettore \bm{u}_i è normalizzato, cioè ha lunghezza unitaria.
\bm{V}_j = \bm{U}_j per ogni j = 1, 2, \ldots, k:
Lo span dei primi j vettori \bm{v}_i è lo stesso dello span dei primi j vettori ortonormali \bm{u}_i, dove
\bm{V}_j = \text{span}(\bm{v}_1, \bm{v}_2, \ldots, \bm{v}_j)
e
\bm{U}_j = \text{span}(\bm{u}_1, \bm{u}_2, \ldots, \bm{u}_j) .
Proof. Dati k vettori \bm{v}_1, \bm{v}_2, , \bm{v}_k che sono linearmente indipendenti, notiamo che \|\bm{v}_i\|_2 \neq 0 per ogni i = 1, 2, \ldots, k. Quindi, possiamo sempre normalizzare il primo vettore \bm{v}_1 definendo \bm{u}_1 = \frac{\bm{v}_1}{\|\bm{v}_1\|_2}. La dimostrazione procede per induzione.
Passo 1:
Per k = 1, il teorema è ovviamente vero, poiché abbiamo \bm{u}_1 = \frac{\bm{v}_1}{\|\bm{v}_1\|_2}, che soddisfa tutte le condizioni richieste.
Passo 2:
Supponiamo che il teorema sia vero per k - 1 vettori. Ovvero, assumiamo di avere già trovato k - 1 vettori ortonormali \bm{u}_1, \bm{u}_2, , \bm{u}_{k-1} tali che:
\bm{u}_1 = \frac{\bm{v}_1}{\|\bm{v}_1\|_2}, \quad \bm{V}_j = \bm{U}_j \text{ per } j = 1, 2, \ldots, k - 1
Definiamo ora il vettore ausiliario \bm{w}_k e il vettore ortonormale \bm{u}_k come segue:
\begin{aligned} \bm{w}_k &= \bm{v}_k - \sum_{i=1}^{k-1} \beta_i \bm{u}_i, \\ \bm{u}_k &= \alpha \bm{w}_k, \end{aligned}
dove i coefficienti \alpha e \beta_i devono essere scelti in modo che \bm{u}_k \bot \bm{u}_i per ogni i = 1, 2, \ldots, k - 1 e \|\bm{u}_k\|_2 = 1.
Calcoliamo il prodotto scalare di \bm{w}_k con \bm{u}_j:
\bm{w}_k \cdot \bm{u}_j = \bm{v}_k \cdot \bm{u}_j - \sum_{i=1}^{k-1} \beta_i \bm{u}_i \cdot \bm{u}_j = \bm{v}_k \cdot \bm{u}_j - \beta_j \quad \text{per } j = 1, 2, \ldots, k - 1
Impostando \bm{w}_k \cdot \bm{u}_j = 0, otteniamo:
\beta_j = \bm{v}_k \cdot \bm{u}_j \quad \text{per } j = 1, 2, \ldots, k - 1
Per determinare \alpha, imponiamo che \|\bm{u}_k\|_2 = 1:
1 = \|\bm{u}_k\|_2^2 = \bm{u}_k \cdot \bm{u}_k = \alpha^2 (\bm{w}_k \cdot \bm{w}_k) = \alpha^2 \|\bm{w}_k\|_2^2
Da cui si ottiene \alpha = \frac{1}{\|\bm{w}_k\|_2}. È necessario che \bm{w}_k \neq \bm{0}; altrimenti, avremmo:
\bm{0} = \bm{v}_k - \sum_{i=1}^{k-1} \beta_i \bm{u}_i
Poiché \bm{U}_{k-1} = \bm{V}_{k-1}, esisterebbero k-1 scalari \gamma_i per cui:
\bm{v}_k = \sum_{i=1}^{k-1} \beta_i \bm{u}_i = \sum_{i=1}^{k-1} \gamma_i \bm{v}_i
Questo contraddice l’indipendenza lineare dei vettori \bm{v}_i.
Passo 3:
Infine, dobbiamo verificare che \bm{U}_k = \bm{V}_k. Consideriamo una combinazione lineare generica dei vettori \bm{v}_i:
\bm{z} = \sum_{i=1}^{k} \eta_i \bm{v}_i
Mostriamo che \bm{z} \in \bm{U}_k. Per l’ipotesi induttiva, esistono k-1 scalari \zeta_i tali che:
\sum_{i=1}^{k-1} \eta_i \bm{v}_i = \sum_{i=1}^{k-1} \zeta_i \bm{u}_i
Utilizzando la relazione:
\bm{v}_k = \frac{\bm{u}_k}{\alpha} + \sum_{i=1}^{k-1} \beta_i \bm{u}_i
Otteniamo:
\bm{z} = \frac{\eta_k}{\alpha} \bm{u}_k + \eta_k \sum_{i=1}^{k-1} \beta_i \bm{u}_i + \sum_{i=1}^{k-1} \zeta_i \bm{u}_i = \frac{\eta_k}{\alpha} \bm{u}_k + \sum_{i=1}^{k-1} (\zeta_i + \eta_k \beta_i) \bm{u}_i
Quindi, \bm{z} \in \bm{U}_k, e poiché \bm{z} è arbitrario, abbiamo \bm{V}_k \subset \bm{U}_k.
Viceversa, se \bm{z} \in \bm{U}_k, possiamo scrivere:
\bm{z} = \sum_{i=1}^{k} \zeta_i \bm{u}_i
e utilizzando la relazione:
\bm{z} = \zeta_k \alpha \left( \bm{v}_k - \sum_{i=1}^{k-1} \beta_i \bm{u}_i \right) + \sum_{i=1}^{k-1} \zeta_i \bm{u}_i = \zeta_k \alpha \bm{v}_k - \sum_{i=1}^{k-1} (\zeta_i - \zeta_k \alpha \beta_i) \bm{u}_i
Per l’ipotesi induttiva, esistono k-1 scalari \omega_i tali che:
\sum_{i=1}^{k-1} (\zeta_i - \zeta_k \alpha \beta_i) \bm{u}_i = \sum_{i=1}^{k-1} \omega_i \bm{v}_i
Quindi, \bm{z} \in \bm{V}_k. Poiché \bm{z} è arbitrario, abbiamo \bm{U}_k \subset \bm{V}_k, e quindi \bm{U}_k = \bm{V}_k.
Questo teorema porta al seguente algoritmo per l’ortonormalizzazione di un insieme di vettori:
Ludwig Otto Hölder 1859-1937.↩︎
O entrambe simultaneamente, ma basta considerare uno dei due casi per procedere!↩︎
Nella figura, l’angolo tra i vettori \bm{a} e \bm{b} è indicato con il simbolo \theta per ragioni tipografiche, anziché con \theta_{\bm{a}\bm{b}}.↩︎
Karl Herman Amandus Schwarz (1843-1921).↩︎