6 Autovalori e Autovettori

Sia \bm{A} \in \Bbb{K}^{n \times n} una matrice quadrata con elementi nel campo \Bbb{K}. Consideriamo la matrice \bm{M}(\lambda), che dipende dallo scalare \lambda \in \Bbb{K}, definita dalla relazione
\bm{M}(\lambda) = \bm{A} - \lambda \bm{I},
dove \bm{I} rappresenta la matrice identità di dimensione n.
Ci poniamo la seguente domanda: per quali valori dello scalare \lambda la matrice \bm{M}(\lambda) e la sua trasposta \bm{M}^T(\lambda) sono singolari?
Una matrice è singolare se il suo determinante è nullo, cioè se non è di rango massimo. Quindi, la condizione di singolarità per \bm{M}(\lambda) e \bm{M}^T(\lambda) si traduce nella richiesta che il loro determinante sia nullo:
\det(\bm{M}(\lambda)) = 0 \quad \text{e} \quad \det(\bm{M}^T(\lambda)) = 0.
Poiché vale la proprietà
\det(\bm{M}(\lambda)) = \det(\bm{M}^T(\lambda)),
ne segue che i valori di \lambda che rendono singolare \bm{M}(\lambda) coincidono con quelli che rendono singolare \bm{M}^T(\lambda). In altre parole, gli scalari \lambda per cui \det(\bm{M}(\lambda)) = 0 sono gli stessi per entrambe le matrici.
Definition 6.1 (Definizione di Autovalore) I valori di \lambda che rendono singolare la matrice \bm{M}(\lambda) – e quindi anche \bm{M}^T(\lambda) – sono detti autovalori di \bm{A}.
6.1 Polinomio Caratteristico
Il determinante della matrice \bm{M}(\lambda) è un polinomio in \lambda di grado n. Questo polinomio si chiama polinomio caratteristico di \bm{A}.
Lemma 6.1 (struttura del polinomio Caratteristico) Il determinante della matrice \bm{M}(\lambda) = \bm{A} - \lambda \bm{I} è un polinomio in \lambda di grado n.
La struttura ricorsiva del determinante può essere descritta come segue. Per una matrice \bm{A} - \lambda \bm{I} di ordine n, possiamo sviluppare il determinante lungo una riga o una colonna. Sviluppando lungo la prima riga, si ottiene:
\det(\bm{M}(\lambda)) = \sum_{j=1}^{n} (-1)^{1+j} (\bm{A}_{1,j} - \lambda \delta_{1,j}) \det(\bm{A}_{-1,-j} - \lambda \bm{I}_{-1,-j}),
dove:
\bm{A}_{-1,-j} è la matrice ottenuta eliminando la prima riga e la j-esima colonna da \bm{A},
\bm{I}_{-1,-j} è la matrice identità corrispondente di ordine ridotto.
Il determinante di ciascuna sottomatrice \bm{A}_{-1,-j} - \lambda \bm{I}_{-1,-j} può essere sviluppato ulteriormente allo stesso modo. Questo processo ricorsivo termina quando il determinante si riduce a una matrice 1 \times 1, il cui determinante è semplicemente l’elemento \bm{A}_{i,i} - \lambda.
Dato che ogni passo dello sviluppo del determinante introduce termini lineari in \lambda, il risultato finale è un polinomio in \lambda di grado al massimo n.
Poiché una matrice è singolare quando il suo determinante è nullo, la condizione di singolarità per \bm{M}(\lambda) ci porta alla seguente definizione.
Definition 6.2 (Definizione: Polinomio Caratteristico) Il polinomio
p_{\bm{A}}(\lambda) = \det(\bm{A} - \lambda \bm{I}),
è detto polinomio caratteristico della matrice \bm{A}.
Per il teorema fondamentale dell’algebra il polinomio caratteristico si fattorizza come prodotto di binomi elevati ad opportuni esponenti m_{a,i}
p_{\bm{A}}(\lambda) = (-1)^{n} (\lambda-\lambda_1)^{m_{a,1}} (\lambda-\lambda_2)^{m_{a,2}}\cdots (\lambda-\lambda_s)^{m_{a,s}}, \tag{6.1}
dove m_{a,1}+m_{a,2}+\cdots+m_{a,s}=n e \lambda_i\neq\lambda_j se i\neq j.
Definition 6.3 (Molteplicità algebrica) Se il polinomio caratteristico di \bm{A} ammette s\leq n zeri distinti che sono gli s autovalori, e si fattorizza come sopra, ad ogni autovalore \lambda_i compete una molteplicità algebrica m_{a,i}.
Se la matrice \bm{M}(\lambda) è singolare per un dato valore dello scalare \lambda, allora deve esistere almeno un vettore \bm{x}\neq\bm{0} tale che
\bm{M}(\lambda)\bm{x} = (\bm{A}-\lambda\bm{I})\bm{x}= \bm{0}.
Analogamente se la matrice \bm{M}(\lambda)^T è singolare per un dato valore dello scalare \lambda, allora deve esistere almeno un vettore \bm{y}\neq\bm{0} tale che
\bm{M}(\lambda)^T\bm{y} = (\bm{A}^T-\lambda\bm{I})\bm{y} = \bm{0},
cioè, trasponendo,
\bm{y}^T\bm{M}(\lambda) = \bm{y}(\bm{A}-\lambda\bm{I}) = \bm{0}^T.
In generale si ha che \bm{x}\neq\bm{y}, anche se si riferiscono allo stesso scalare \lambda che rende singolari \bm{M}(\lambda) e \bm{M}^T(\lambda).
6.2 Autovettori
Definition 6.4 (Autovettore destro) Un vettore colonna \bm{u}\neq\bm{0} è un autovettore destro della matrice \bm{A} rispetto ad uno scalare \lambda se vale la relazione
\bm{A}\bm{u} = \lambda\bm{u}.
Definition 6.5 (Autovettore sinistro) Un vettore riga \bm{w}^T\neq\bm{0} è un autovettore sinistro della matrice \bm{A} rispetto ad uno scalare \lambda se vale la relazione
\bm{w}^T\bm{A} = \lambda\bm{w}^T.
cioè \bm{w} è autovettore di \bm{A}^T.
6.3 Autovalori multipli
Lemma 6.2 (Autovalori Multipli) Se \bm{x}_1, \bm{x}_2, \ldots, \bm{x}_k sono k autovettori associati allo stesso autovalore \lambda_i, allora ogni loro combinazione lineare è anch’essa un autovettore corrispondente allo stesso autovalore.
Proof. Siano \beta_1, \beta_2, \ldots, \beta_k dei scalari arbitrari. Allora, per ogni combinazione lineare degli autovettori \bm{x}_1, \bm{x}_2, \ldots, \bm{x}_k, si ha:
\bm{A}\left(\sum_{j=1}^{k} \beta_j\bm{x}_j\right) = \sum_{j=1}^{k} \beta_j \bm{A}\bm{x}_j = \sum_{j=1}^{k} \beta_j \lambda_i \bm{x}_j = \lambda_i \left(\sum_{j=1}^{k} \beta_j \bm{x}_j\right).
Quindi, la combinazione lineare \sum_{j=1}^{k} \beta_j \bm{x}_j è un autovettore rispetto allo stesso autovalore \lambda_i.
Molteplicità Geometrica
Definition 6.6 (Definizione: Molteplicità Geometrica) La molteplicità geometrica di un autovalore \lambda_i, indicata con m_{g,i}, è il massimo numero di autovettori linearmente indipendenti che possono essere scelti nello spazio \ker(\bm{A} - \lambda_i \bm{I}) associato all’autovalore \lambda_i.
Molteplicità Algebrica
Definition 6.7 (Definizione: Molteplicità Algebrica) La molteplicità algebrica di un autovalore \lambda_i di una matrice \bm{A} è definita come la molteplicità dell’autovalore \lambda_i come radice del polinomio caratteristico di \bm{A}. In altre parole, è il numero di volte che \lambda_i compare come radice del polinomio caratteristico
p_{\bm{A}}(\lambda) = \det(\bm{A} - \lambda \bm{I}),
dove \bm{I} è la matrice identità della stessa dimensione di \bm{A}. La molteplicità algebrica di \lambda_i è quindi il grado di \lambda_i come radice del polinomio caratteristico.
Theorem 6.1 (Molteplicità confronto) La molteplicità algebrica m_{a,i} di un autovalore \lambda_i è sempre maggiore o uguale alla corrispondente molteplicità geometrica m_{g,i}, cioè:
m_{a,i} \geq m_{g,i}.
Proof. Siano \bm{u}_1, \bm{u}_2, , \bm{u}_{m_{g,i}} gli autovettori corrispondenti a \lambda_i, che possiamo sempre considerare ortonormali (se necessario, possiamo ortonormalizzarli usando il processo di Gram-Schmidt).
Se m_{g,i} < n, completiamo con altri n - m_{g,i} vettori per ottenere una base ortonormale. Definiamo \bm{T} come la matrice le cui colonne sono questi vettori:
\bm{T} = \begin{pmatrix} \bm{u}_1 & \bm{u}_2 & \cdots & \bm{u}_{m_{g,i}} & \bm{u}_{m_{g,i}+1} & \cdots & \bm{u}_n \end{pmatrix},
dove \bm{T}^{T} \bm{T} = \bm{I} implica che \bm{T}^{T} = \bm{T}^{-1}.
Consideriamo la matrice \bm{A} trasformata dalla base ortonormale:
\bm{A} \bm{T} = \begin{pmatrix} \lambda_i \bm{u}_1 & \lambda_i \bm{u}_2 & \cdots & \lambda_i \bm{u}_{m_{g,i}} & \bm{w} & \cdots & \bm{z} \end{pmatrix}.
Pertanto, possiamo scrivere:
\bm{T}^{-1} \bm{A} \bm{T} = \bm{T}^T \bm{A} \bm{T} = \begin{pmatrix} \begin{matrix} \lambda_i & & \\ & \ddots & \\ & & \lambda_i \end{matrix} & \bm{B} \\ \hline \bm{0} & \bm{C} \end{pmatrix}.
Dove \bm{B} e \bm{C} rappresentano blocchi della matrice. Pertanto, il determinante del polinomio caratteristico è:
\begin{aligned} \det(\bm{A} - \lambda \bm{I}) &= \det(\bm{T}^{-1} (\bm{A} - \lambda \bm{I}) \bm{T}) \\ &= \det(\bm{T}^{-1} \bm{A} \bm{T} - \lambda \bm{I}) \\ &= \left| \begin{array}{cc} \begin{matrix} \lambda_i - \lambda & \\ & \ddots \\ & & \lambda_i - \lambda \end{matrix} & \bm{B} \\ \hline \bm{0} & \bm{C} - \lambda \bm{I} \end{array} \right| \\ &= (\lambda_i - \lambda)^{m_{g,i}} \det(\bm{C} - \lambda \bm{I}). \end{aligned}
Pertanto, \lambda_i è una radice del polinomio caratteristico con molteplicità almeno m_{g,i}, ma può essere superiore se \det(\bm{C} - \lambda_i \bm{I}) = 0. Concludiamo che m_{a,i} \geq m_{g,i}.
6.4 Matrici reali simmetriche e hermitiane
Ricordiamo le definizioni già introdotte nel capitolo riguardante vettori e matrici. Una matrice quadrata \bm{A} si dice simmetrica se soddisfa la condizione \bm{A} = \bm{A}^T, dove \bm{A}^T è la trasposta di \bm{A}. Allo stesso modo, una matrice quadrata è ermitiana se \bm{A} = \bm{A}^H, dove \bm{A}^H denota la trasposizione coniugata (o matrice di Hermite).
Definition 6.8 (Matrice normale) Una matrice quadrata \bm{A} si dice normale se \bm{A}\bm{A}^H=\bm{A}^H\bm{A}.
Le proprietà di simmetria per matrici reali o di ermiticità per matrici complesse impongono condizioni molto forti sugli autovalori e sugli autovettori. In particolare, il seguente teorema è valido:
Theorem 6.2 Una matrice reale simmetrica o ermitiana ha solo autovalori reali.
Proof. Consideriamo una matrice reale \bm{A} simmetrica. Poiché ogni matrice reale simmetrica è anche ermitiana, il caso della matrice ermitiana è sufficientemente generico. Supponiamo quindi che \bm{A} sia ermitiana e che \lambda sia un autovalore con il corrispondente autovettore \bm{u} \neq \bm{0}. Moltiplicando a sinistra per \bm{u}^H, otteniamo:
\bm{A} \bm{u} = \lambda \bm{u}
da cui segue:
\bm{u}^H \bm{A} \bm{u} = \lambda \bm{u}^H \bm{u} = \lambda \|\bm{u}\|_2^2.
Isoliamo l’autovalore \lambda:
\bm{u}^H \bm{A} \bm{u} = \lambda \|\bm{u}\|_2^2 \quad \Rightarrow \quad \lambda = \frac{\bm{u}^H \bm{A} \bm{u}}{\|\bm{u}\|_2^2}.
Dalla definizione di norma e autovettore, il denominatore \|\bm{u}\|_2^2 è sicuramente un numero reale strettamente positivo. Inoltre, il numeratore \bm{u}^H \bm{A} \bm{u} è reale, come dimostrato dalla seguente sequenza di uguaglianze:
\begin{aligned} \bm{u}^H \bm{A} \bm{u} &= (\bm{u}^H \bm{A} \bm{u})^T, \\ &= \overline{(\bm{u}^H \bm{A} \bm{u})^T}, \\ &= \overline{(\bm{u}^H \bm{A} \bm{u})^H}, \\ &= \overline{\bm{u}^H \bm{A}^H \bm{u}}, \\ &= \overline{\bm{u}^H \bm{A} \bm{u}}. \end{aligned}
Poiché \bm{A} = \bm{A}^H, risulta che \bm{u}^H \bm{A} \bm{u} \in \Bbb{R}. Essendo \lambda un rapporto tra numeri reali, anche \lambda è reale.
Theorem 6.3 (Esistenza degli Autovettori Reali) Per ogni autovalore di una matrice reale simmetrica esiste almeno un autovettore che ha solo componenti reali.
Proof. Sia \bm{A} una matrice reale simmetrica e \lambda un autovalore di \bm{A}. Supponiamo che \bm{u} = \bm{A} + \mathrm{i} \bm{b} sia un autovettore associato a \lambda, dove \bm{A} e \bm{b} sono rispettivamente le componenti reali e complesse di \bm{u}. Allora abbiamo:
\bm{A} (\bm{A} + \mathrm{i} \bm{b}) = \lambda (\bm{A} + \mathrm{i} \bm{b}).
Separando le parti reale e immaginaria, otteniamo:
\bm{A} \bm{A} + \mathrm{i} \bm{A} \bm{b} = \lambda \bm{A} + \mathrm{i} \lambda \bm{b}.
Eguagliando le parti reali e immaginarie, otteniamo:
\bm{A} \bm{A} = \lambda \bm{A} \quad \text{e} \quad \bm{A} \bm{b} = \lambda \bm{b}.
Poiché \bm{u} \neq \bm{0}, almeno uno dei vettori \bm{A} o \bm{b} deve essere non nullo. Pertanto, almeno uno dei vettori reali \bm{A} o \bm{b} è un autovettore di \bm{A} rispetto all’autovalore \lambda.
Theorem 6.4 (Ortogonalità degli Autovettori) Sia \bm{A} una matrice reale simmetrica o ermitiana, e siano \lambda e \mu due autovalori distinti di \bm{A} con i corrispondenti autovettori \bm{u} e \bm{v}. Allora, gli autovettori \bm{u} e \bm{v} sono ortogonali, cioè:
\bm{u} \cdot \bm{v} = 0.
Proof. Consideriamo le seguenti equazioni:
\begin{aligned} \bm{A} \bm{u} &= \lambda \bm{u}, \\ \bm{A} \bm{v} &= \mu \bm{v}. \end{aligned}
Moltiplichiamo la prima equazione a sinistra per \bm{v}^H e la seconda per \bm{u}^H:
\begin{aligned} \bm{v}^H \bm{A} \bm{u} &= \lambda \bm{v}^H \bm{u}, \\ \bm{u}^H \bm{A} \bm{v} &= \mu \bm{u}^H \bm{v}. \end{aligned}
Poiché \bm{A} è simmetrica o ermitiana, abbiamo \bm{v}^H \bm{A} \bm{u} = \bm{u}^H \bm{A} \bm{v}. Quindi:
\lambda \bm{v}^H \bm{u} = \mu \bm{u}^H \bm{v}.
Da cui segue:
\lambda \bm{v}^H \bm{u} = \mu \bm{v}^H \bm{u} \quad \Rightarrow \quad (\lambda - \mu) \bm{v}^H \bm{u} = 0.
Poiché \lambda \neq \mu, abbiamo:
\bm{v}^H \bm{u} = 0,
cioè \bm{u} e \bm{v} sono ortogonali.
Infine vale la seguente osservazione.
Infine, una proprietà fondamentale delle matrici reali simmetriche o ermitiane è che possono essere diagonalizzate mediante opportune trasformazioni chiamate trasformazioni di similitudine. In questo caso particolare, tali trasformazioni coinvolgono matrici ortogonali o unitarie. Di seguito forniamo la definizione di queste matrici.
Definition 6.9 (Matrice ortogonale) Una matrice \bm{A} è ortogonale se la sua trasposta coincide con la sua inversa. Formalmente,
\bm{A}^T = \bm{A}^{-1}.
Definition 6.10 (Matrice unitaria) Una matrice \bm{A} è unitaria se la sua trasposta coniugata coincide con la sua inversa. Formalmente,
\bm{A}^H = \bm{A}^{-1}.
6.5 Diagonalizzazione
Theorem 6.5 (Teorema di Diagonalizzazione) Sia \bm{A} una matrice reale simmetrica. Allora esiste una matrice \bm{U} ortogonale tale che:
\bm{U}^T \bm{A} \bm{U} = \begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix},
dove \lambda_1, \lambda_2, , \lambda_n sono gli autovalori della matrice \bm{A}.
Proof. La dimostrazione si basa su un argomento per induzione.
Base dell’induzione: Il teorema è vero per le matrici 1 \times 1.
Passo induttivo: Sia \lambda_1 un autovalore di \bm{A} (reale per il Teorema Theorem 6.2) e \bm{w}_1 un autovettore corrispondente di norma 1 (che possiamo assumere a valori reali per lil teorema Theorem 6.3.
Possiamo completare \bm{w}_1 a una base ortonormale \bm{w}_1, \bm{w}_2, , \bm{w}_n (vedi note su norme e prodotti scalari). Sia \bm{U} la matrice le cui colonne sono i vettori \bm{w}_1, \bm{w}_2, , \bm{w}_n.
Allora \bm{U}^T \bm{U} = \bm{I}, infatti:
(\bm{U}^T \bm{U})_{i,j} = \sum_{k=1}^{n} U_{k,i} U_{k,j} = \bm{U}_{\bullet,i} \cdot \bm{U}_{\bullet,j} = \delta_{i,j}.
Inoltre, dato che \bm{A} \bm{U}_{\bullet,1} = \lambda_1 \bm{U}_{\bullet,1}, otteniamo:
\bm{A} \bm{U} = \bm{U} \begin{pmatrix} \lambda_1 & \boldsymbol{\eta} \\ \bm{0} & \bm{B} \end{pmatrix},
dove \boldsymbol{\eta} è un vettore riga e \bm{B} è una matrice quadrata non ancora specificata. Moltiplicando a sinistra per \bm{U}^T, otteniamo:
\bm{U}^T \bm{A} \bm{U} = \begin{pmatrix} \lambda_1 & \boldsymbol{\eta}^T \\ \bm{0} & \bm{B} \end{pmatrix}.
Dato che \bm{A} è simmetrica, segue che \bm{U}^T \bm{A} \bm{U} è simmetrica. Pertanto, la matrice a blocchi a destra è simmetrica, quindi \boldsymbol{\eta} = \bm{0} e \bm{B} è simmetrica.
Applicando l’induzione, esiste una matrice \bm{S} ortogonale tale che:
\bm{S}^T \bm{B} \bm{S} = \begin{pmatrix} \lambda_2 & & & \\ & \lambda_3 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix}.
Pertanto, abbiamo:
\begin{aligned} \begin{pmatrix} 1 & \bm{0}^T \\ \bm{0} & \bm{S}^T \end{pmatrix} \bm{U}^T \bm{A} \bm{U} \begin{pmatrix} 1 & \bm{0}^T \\ \bm{0} & \bm{S} \end{pmatrix} &= \begin{pmatrix} 1 & \bm{0}^T \\ \bm{0} & \bm{S}^T \end{pmatrix} \begin{pmatrix} \lambda_1 & \bm{0}^T \\ \bm{0} & \bm{B} \end{pmatrix} \begin{pmatrix} 1 & \bm{0}^T \\ \bm{0} & \bm{S} \end{pmatrix} \\ &= \begin{pmatrix} \lambda_1 & \bm{0}^T \\ \bm{0} & \bm{S}^T \bm{B} \bm{S} \end{pmatrix} \\ &= \begin{pmatrix} \lambda_1 & \bm{0}^T \\ \bm{0} & \begin{pmatrix} \lambda_2 & & & \\ & \lambda_3 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix} \end{pmatrix}. \end{aligned}
Quindi, ponendo:
\bm{U} = \bm{U} \begin{pmatrix} 1 & \bm{0}^T \\ \bm{0} & \bm{S} \end{pmatrix},
otteniamo che \bm{U} è la matrice ortogonale cercata.
6.6 Diagonalizzazione di matrici Hermitiane
Theorem 6.6 (Teorema di Diagonalizzazione per matrici Hermitiane) Sia \bm{A} una matrice hermitiana. Allora esiste una matrice unitaria \bm{U} tale che:
\bm{U}^H \bm{A} \bm{U} = \begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix},
dove \lambda_1, \lambda_2, , \lambda_n sono gli autovalori della matrice \bm{A}.
Proof. La dimostrazione di questo teorema segue un argomento simile a quello del teorema di diagonalizzazione per matrici simmetriche, con le seguenti modifiche:
Sostituzione dei Termini: Sostituiamo i termini “simmetrico” e “ortogonale” con “hermitiano” e “unitario”, rispettivamente.
Trasposizione e Coniugazione: Tutte le trasposizioni di matrici reali, indicate con (\cdot)^T, devono essere reinterpretate come trasposizioni con coniugazione, indicate con (\cdot)^H.
In altre parole, se \bm{A} è hermitiana, per ogni autovalore \lambda e autovettore \bm{u} della matrice \bm{A}, si ha:
\bm{A} \bm{u} = \lambda \bm{u}
Applicando la trasposizione con coniugazione, otteniamo:
\bm{u}^H \bm{A} \bm{u} = \lambda \|\bm{u}\|_2^2.
Da ciò, possiamo dedurre che l’autovalore \lambda è reale e, quindi, la matrice \bm{A} può essere diagonalizzata mediante una matrice unitaria \bm{U}, che riporta gli autovalori lungo la diagonale.
Quindi, il processo di diagonalizzazione per matrici hermitiane è simile a quello per matrici simmetriche, con l’aggiunta della coniugazione complessa.
6.7 Spettro, raggio spettrale e localizzazione degli autovalori sul piano complesso
Definition 6.11 (Spettro) L’insieme degli autovalori di una matrice \bm{A} si chiama spettro della matrice e si indica usualmente col simbolo \sigma(\bm{A}).
Definition 6.12 (Raggio spettrale) Data una matrice quadrata \bm{A} con autovalori \lambda_1, \lambda_2, \ldots,\lambda_n il numero
\varrho(\bm{A})=\max\{|\lambda_i|\,:\,i=1,2,\ldots,n\},
è detto raggio spettrale della matrice \bm{A}.
6.8 Teorema dei cerchi di Gerschgorin
Theorem 6.7 (Teorema dei cerchi di Gerschgorin) Sia \bm{A} \in \Bbb{K}^{n \times n}. Definiamo l’insieme dei numeri complessi:
S = \bigcup_{i=1}^n \left\{ z \in \Bbb{C} : \left| A_{i,i} - z \right| \leq \sum_{j=1, \, j \ne i}^n \left| A_{i,j} \right| \right\}.
Allora, ogni autovalore di \bm{A} appartiene all’insieme S.
Proof. Sia \lambda un autovalore di \bm{A} con il corrispondente autovettore \bm{u}. Sia k l’indice della componente di \bm{u} con il modulo massimo:
|u_k| = \max_{i=1,\ldots,n} |u_i|.
Consideriamo l’equazione caratteristica:
\bm{A} \bm{u} - \lambda \bm{u} = \bm{0}.
Analizzando la k-esima componente, otteniamo:
\sum_{j=1}^{n} A_{k,j} u_j - \lambda u_k = 0.
Isoliamo il termine \lambda u_k:
(A_{k,k} - \lambda) u_k = - \sum_{j=1, \, j \ne k}^{n} A_{k,j} u_j.
Calcoliamo il modulo di entrambi i membri dell’equazione e dividiamo per |u_k| > 0:
|A_{k,k} - \lambda| \leq \sum_{j=1, \, j \ne k}^{n} |A_{k,j}| \left| \frac{u_j}{u_k} \right|.
Poiché \left| \frac{u_j}{u_k} \right| \leq 1, otteniamo:
|A_{k,k} - \lambda| \leq \sum_{j=1, \, j \ne k}^{n} |A_{k,j}|.
Quindi, \lambda soddisfa l’inequazione che definisce il cerchio di Gerschgorin centrato in A_{k,k} con raggio \sum_{j=1, \, j \ne k}^{n} |A_{k,j}|. Pertanto, \lambda appartiene all’insieme S.
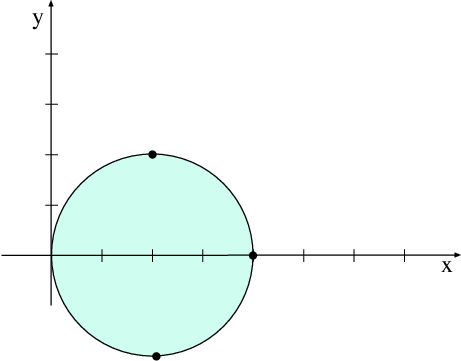
\bm{A} = \begin{pmatrix} 1+\mathrm{i} & \frac{1}{2} & \frac{1}{2} \\ 1 & 2 & 0 \\ \frac{1}{4} & -\frac{1}{4} & 6+\mathrm{i} \end{pmatrix},\qquad \sigma(\bm{A}) = \left\{\begin{matrix} \lambda_1 &= 0.69 + 0.82\mathrm{i}, \\ \lambda_2 &= 2.29 + 0.18\mathrm{i}, \\ \lambda_3 &= 6.02 + 1.01\mathrm{i} \end{matrix}\right.
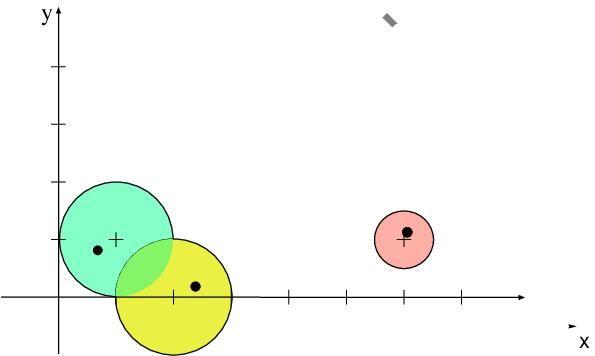
Possiamo avere anche situazioni insolite. Per esempio,
\bm{A} = \begin{pmatrix} 4 & 0 & 0 \\ 0 & 2 & 2 \\ 0 & -2 & 2 \end{pmatrix},\qquad \sigma(\bm{A}) = \begin{pmatrix} \lambda_1 &=& 4,\\ \lambda_2 &=& 2(1+i),\\ \lambda_3 &=& 2(1-i) \end{pmatrix}
6.9 Matrici a Diagonale Dominante
Definition 6.13 (Dominanza Diagonale) Una matrice quadrata \bm{A} è chiamata diagonale dominante se soddisfa la seguente condizione per ogni riga i:
|A_{i,i}| \geq \sum_{j=1, \, j \ne i}^{n} |A_{i,j}|,
e la disuguaglianza deve essere stretta per almeno un indice i. Se la disuguaglianza è stretta per ogni indice i, allora la matrice \bm{A} è detta diagonale strettamente dominante.
Theorem 6.8 (Teorema sulla Diagonale Dominante) Se una matrice \bm{A} è a diagonale strettamente dominante, allora è non singolare.
Proof. Per dimostrare che una matrice a diagonale strettamente dominante è non singolare, consideriamo il fatto che il cerchio di Gerschgorin centrato in A_{i,i} con raggio \sum_{j=1, \, j \ne i}^{n} |A_{i,j}| non può contenere l’origine se la matrice è a diagonale strettamente dominante. Questo implica che lo zero non può essere un autovalore della matrice \bm{A}. Di conseguenza, la matrice \bm{A} non è singolare.
6.10 Matrici Definite Positive
Definition 6.14 (Matrice Definita Positiva) Una matrice quadrata \bm{A} è definita positiva se soddisfa le seguenti condizioni per ogni vettore \bm{u} \in \Bbb{K}^n:
\bm{u}^T \bm{A} \bm{u} > 0 per ogni vettore \bm{u} \neq \mathbf{0}
\bm{u}^T \bm{A} \bm{u} = 0 solo se \bm{u} = \mathbf{0}
Se la seconda condizione non è soddisfatta e \bm{u}^T \bm{A} \bm{u} \geq 0 per ogni \bm{u}, allora la matrice \bm{A} è definita semipositiva.
Definition 6.15 (Matrice Simmetrica e Definita Positiva) Quando una matrice definita positiva è anche simmetrica, essa è detta simmetrica e definita positiva. Questa proprietà è abbreviata in SPD, dall’inglese Symmetric Positive Definite.
6.11 Autovalori di Matrici SPD
Theorem 6.9 (Teorema degli Autovalori di Matrici SPD) Se \bm{A} è una matrice definita positiva, allora tutti i suoi autovalori sono positivi.
Proof. Sia \lambda un autovalore di \bm{A}, e sia \bm{u} un autovettore associato, cioè:
\bm{A} \bm{u} = \lambda \bm{u}
Moltiplicando entrambi i lati dell’equazione per \bm{u}^T, otteniamo:
\bm{u}^T \bm{A} \bm{u} = \lambda \bm{u}^T \bm{u} = \lambda \| \bm{u} \|_2^2
Poiché \bm{A} è definita positiva, \bm{u}^T \bm{A} \bm{u} > 0 per ogni \bm{u} \neq 0, il che implica che:
\lambda = \frac{\bm{u}^T \bm{A} \bm{u}}{\| \bm{u} \|_2^2} > 0
Pertanto, ogni autovalore \lambda di \bm{A} è positivo.
6.12 Determinante di Matrici SPD
Theorem 6.10 (Determinante di una Matrice SPD) Se \bm{A} è una matrice simmetrica e definita positiva (SPD), allora il suo determinante è positivo:
|\bm{A}| > 0.
Proof. Dato che \bm{A} è una matrice simmetrica e definita positiva, esiste una matrice ortogonale reale \bm{U} e una matrice diagonale \boldsymbol{\Lambda} con autovalori positivi, tali che:
\bm{A} = \bm{U}^T \boldsymbol{\Lambda} \bm{U},
dove \boldsymbol{\Lambda} = \text{diag}(\lambda_1, \lambda_2, \ldots, \lambda_n) e \lambda_i > 0 sono gli autovalori di \bm{A}. Utilizzando la proprietà del determinante per la decomposizione in fattori ortogonali:
\begin{aligned} |\bm{A}| &= |\bm{U}^T \boldsymbol{\Lambda} \bm{U}|\\ &= |\bm{U}^T| |\boldsymbol{\Lambda}| |\bm{U}| \\ &= |\bm{U}|^T |\boldsymbol{\Lambda}| |\bm{U}| \\ &= |\boldsymbol{\Lambda}| \\ &= \lambda_1 \lambda_2 \cdots \lambda_n > 0, \end{aligned}
dove |\bm{U}|^T |\bm{U}| = |\bm{U}^T \bm{U}| = |\bm{I}| = 1.
Poiché \lambda_i > 0 per tutti i, il determinante |\bm{A}| è positivo.
6.13 Blocchi Diagonali di Matrici SPD
Theorem 6.11 (Proprietà dei Blocchi Diagonali in Matrici SPD) Sia \bm{M} \in \Bbb{K}^{(n+m) \times (n+m)} una matrice SPD della forma:
\bm{M} = \begin{pmatrix} \bm{A} & \bm{B}^T \\ \bm{B} & \bm{C} \end{pmatrix},
dove \bm{A} \in \Bbb{K}^{n \times n} e \bm{C} \in \Bbb{K}^{m \times m}, allora sia \bm{A} che \bm{C} sono anch’esse SPD.
Proof. Consideriamo un vettore \boldsymbol{\omega} della forma:
\boldsymbol{\omega} = \begin{pmatrix} \bm{u} \\ \mathbf{0} \end{pmatrix},
dove \bm{u} \in \Bbb{K}^n. Calcoliamo:
\begin{aligned} 0 &\leq \boldsymbol{\omega}^T \bm{M} \boldsymbol{\omega} \\ &= \begin{pmatrix} \bm{u}^T & \mathbf{0}^T \end{pmatrix} \begin{pmatrix} \bm{A} & \bm{B}^T \\ \bm{B} & \bm{C} \end{pmatrix} \begin{pmatrix} \bm{u} \\ \mathbf{0} \end{pmatrix} \\ &= \bm{u}^T \bm{A} \bm{u}. \end{aligned}
Poiché \boldsymbol{\omega}^T \bm{M} \boldsymbol{\omega} = \bm{u}^T \bm{A} \bm{u} è sempre non negativo e uguale a zero solo se \bm{u} = \mathbf{0}, segue che \bm{A} deve essere SPD.
Analogamente, considerando un vettore della forma:
\boldsymbol{\omega} = \begin{pmatrix} \mathbf{0} \\ \bm{u} \end{pmatrix},
si mostra che \bm{C} è SPD.
6.14 Teorema di Sylvester1
Theorem 6.12 (Teorema di Sylvester) Sia \bm{M} \in \Bbb{R}^{n \times n} una matrice con la seguente partizione:
\bm{M} = \begin{pmatrix} \bm{A}^{(k)} & \bm{B}^T \\ \bm{B} & \bm{C} \end{pmatrix},
dove \bm{A}^{(k)} \in \Bbb{R}^{k \times k} e \bm{C} \in \Bbb{R}^{(n-k) \times (n-k)}. Allora, le seguenti affermazioni sono equivalenti:
- \bm{M} è simmetrica e definita positiva (SPD).
- |\bm{A}^{(k)}| > 0 per ogni k = 1, 2, \ldots, n.
Proof.
[1 \Rightarrow 2]
Se \bm{M} è SPD, allora ogni blocco principale \bm{A}^{(k)} deve essere SPD. Questo implica che |\bm{A}^{(k)}| > 0 per ogni k.
[2 \Rightarrow 1]
La dimostrazione si effettua per induzione sul numero di righe e colonne della matrice.
Caso base (n = 1): Quando n = 1, la matrice \bm{M} è uno scalare, e il teorema è triviale poiché \bm{M} è SPD se e solo se il suo valore è positivo.
Passo induttivo (n > 1): Supponiamo che il teorema sia vero per matrici di dimensione n - 1 (ipotesi induttiva). Consideriamo una matrice \bm{M} di dimensione n e partizioniamola come segue:
\bm{M} = \begin{pmatrix} \bm{A}^{(n-1)} & \bm{b} \\ \bm{b}^T & A_{n,n} \end{pmatrix},
dove \bm{A}^{(n-1)} è una matrice (n-1) \times (n-1), e \bm{b} è un vettore colonna di dimensione n-1.
Definiamo la matrice di blocco \bm{L} come:
\bm{L} = \begin{pmatrix} \bm{I} & -(\bm{A}^{(n-1)})^{-T} \bm{b} \\ \mathbf{0} & 1 \end{pmatrix},
e la sua trasposta:
\bm{L}^T = \begin{pmatrix} \bm{I} & \mathbf{0} \\ -\bm{b}^T (\bm{A}^{(n-1)})^{-1} & 1 \end{pmatrix}.
Calcoliamo:
\bm{L}^T \bm{M} \bm{L} = \begin{pmatrix} \bm{A}^{(n-1)} & \mathbf{0} \\ \mathbf{0} & A_{n,n} - \bm{b}^T \bm{A}^{(n-1)} \bm{b} \end{pmatrix}.
Dal momento che |\bm{L}| = |\bm{L}^T| = 1, abbiamo:
\begin{aligned} |\bm{M}| &= |\bm{L}^{-T} \bm{L}^T \bm{M} \bm{L} \bm{L}^{-1}|\\ &= |\bm{L}^{-T}| |\bm{L}^T \bm{M} \bm{L}| |\bm{L}^{-1}| \\ &= \begin{vmatrix} \bm{A}^{(n-1)} & \mathbf{0} \\ \mathbf{0} & A_{n,n} - \bm{b}^T \bm{A}^{(n-1)} \bm{b} \end{vmatrix} \\ &= |\bm{A}^{(n-1)}| \cdot (A_{n,n} - \bm{b}^T \bm{A}^{(n-1)} \bm{b}). \end{aligned}
Per ipotesi induttiva, \bm{A}^{(n-1)} è SPD, quindi |\bm{A}^{(n-1)}| > 0. Inoltre, |\bm{M}|> 0 implica che:
A_{n,n} - \bm{b}^T \bm{A}^{(n-1)} \bm{b} > 0.
Consideriamo ora un vettore \bm{z} generico e poniamo \boldsymbol{\omega} = \bm{L}^{-1} \bm{z}, con la partizione:
\boldsymbol{\omega} = \begin{pmatrix} \bm{u} \\ \alpha \end{pmatrix},
dove \bm{u} è un vettore di dimensione n-1 e \alpha è uno scalare. Allora:
\begin{aligned} \bm{z}^T \bm{M} \bm{z} &= \boldsymbol{\omega}^T \bm{L}^T \bm{M} \bm{L} \boldsymbol{\omega} \\ &= \begin{pmatrix} \bm{u}^T & \alpha \end{pmatrix} \begin{pmatrix} \bm{A}^{(n-1)} & \mathbf{0} \\ \mathbf{0} & A_{n,n} - \bm{b}^T \bm{A}^{(n-1)} \bm{b} \end{pmatrix} \begin{pmatrix} \bm{u} \\ \alpha \end{pmatrix} \\ &= \bm{u}^T \bm{A}^{(n-1)} \bm{u} + \alpha^2 \cdot (A_{n,n} - \bm{b}^T \bm{A}^{(n-1)} \bm{b}). \end{aligned}
Poiché \bm{A}^{(n-1)} è SPD per ipotesi induttiva, abbiamo che:
\bm{z}^T \bm{M} \bm{z} \geq 0.
Se \bm{z}^T \bm{M} \bm{z} = 0, allora \alpha = 0 e \bm{u} = \mathbf{0}, quindi \bm{z} = \bm{L}^{-1} \mathbf{0} = \mathbf{0}. Di conseguenza, \bm{M} è SPD.